
最近、自然言語処理技術の進歩によって、ChatGPTなどLLM(大規模言語モデル:Large Language Models)のビジネス利用の需要が高まっています。APIを通してLLMの機能をシステムやアプリケーションに統合することで、顧客サービス、コンテンツ作成、データ分析など、さまざまなプロセスの自動化に役立つツールを開発することができます。
しかしLLMのビジネス利用には、機密情報の取り扱いなどに関してセキュリティ上の懸念が生じます。この記事では、LLMのビジネス利用に伴うセキュリティ上の懸念点について解説し、主な対策について紹介します。
◆LLM利用におけるセキュリティ上の懸念
LLMは、大量のデータを学習しテキストの解析や自動生成を行うという特性上、特にビジネス利用においてはセキュリティ上の懸念があります。情報漏洩などの重大なリスクを回避するためには、万全のセキュリティ体制を構築する必要があります。下図はLLM APIを利用した顧客サービスにおけるセキュリティ体制の一例です。
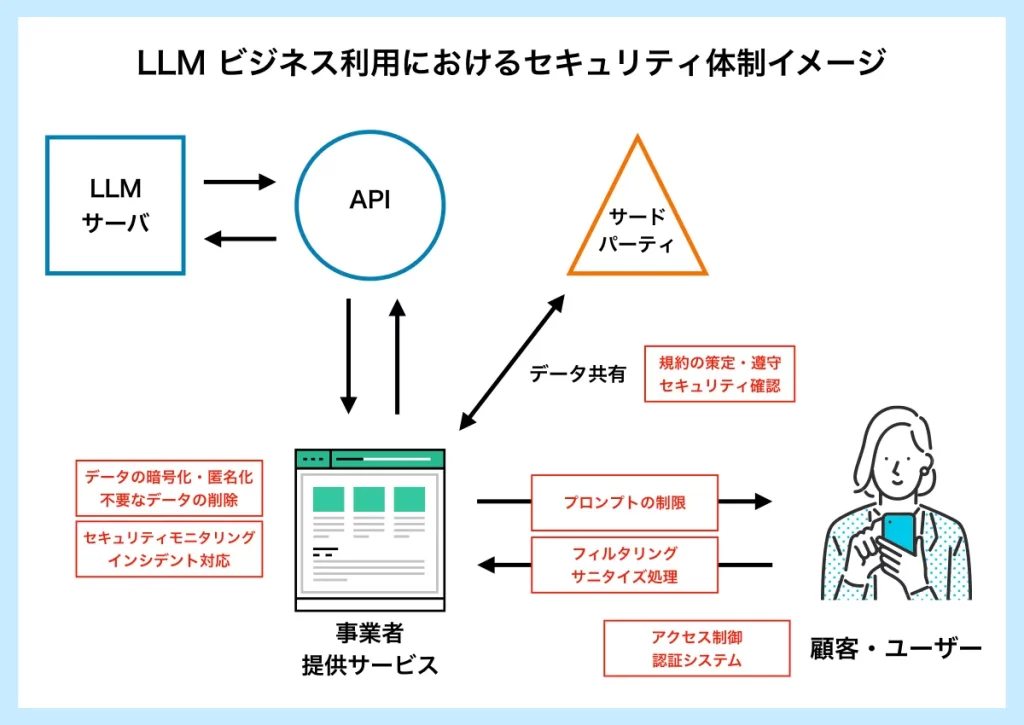
以下にLLMのビジネス利用の際に事業者が注意すべき具体的な懸念点を挙げ、主な対策について解説します。
◇データプライバシーの問題
懸念点の1つは、データ漏洩の潜在的なリスクです。LLMは常に大量のデータを処理する必要があるため、入力されたデータはクラウドサーバに送信されます。そのプロセスでサイバー攻撃を受けることで機密情報が漏洩してしまう危険があります。特に顧客の名前、住所、クレジットカード番号などの個人情報データが悪意ある第三者に渡った場合、ID盗難や金融詐欺などの犯罪に利用される可能性があります。
◾︎対策
・適切なデータ処理
データ漏洩への対策としてまず考えられるのは、データの暗号化・匿名化などの保護措置を講じた上で必要なデータのみをAPIプロバイダーと共有することです。また、不要になったデータは適切に削除するなど、厳格なポリシーを策定し遵守する必要があります。
・アクセス制御と認証システムの実装
不正なアクセスからのデータ漏洩を防ぐためにはサービスへのアクセス制御を行い、安全性の高い認証システムを実装することも重要です。また、事業者側が正しいリスク認識を行い、従業員のセキュリティ意識の向上を図ることも大切です。
・サードパーティとの規約策定・遵守
データをサードパーティと共有する際には、契約や合意事項を明確にし、適切なデータ保護対策が実施されているか確認することが重要です。万一セキュリティインシデントが生じた際の責任の分担や対応手順なども明確に定めておく必要があります。
・信頼できるAPIプロバイダーを選ぶ
前提として、クライアントのデータ保護に高い実績を持つAPIプロバイダーを選択することが重要です。LLM APIはデータをプロバイダーに送信するため、場合によってはデータがLLMのトレーニングに利用される可能性もあります。あらかじめAPIプロバイダーのプライバシーポリシーなどをよく確認し、送信したデータがどのように処理されるのか認識しておく必要があります。
弊社(SELF株式会社)では、Azure OpenAIを利用し、GPTモデルと連携したサービスを提供しています。OpenAIは、API経由で送信されたデータはモデルのトレーニングに利用しないことがポリシーに明記してあります。 →SELFのチャットボットサービスについて、詳しくはこちらをご覧ください。

◇プロンプト・インジェクション攻撃
プロンプト(prompt)とは、ユーザーがLLMに与える指示を含むテキストのことで、LLMはプロンプトを解析して適切な回答を返します。
LLM利用の懸念点として、意図的に不正なプロンプトを注入(インジェクション)してモデルを操作する「プロンプト・インジェクション攻撃」があります。これによってモデルがサービス側の意図しない応答をしてしまったり、不適切な情報を開示してしまう可能性があります。これは、LLMが医療や金融などの重要なタスクに使用される場合、特に危険です。
◾︎対策
・不正なプロンプトの排除
こうした攻撃を防止するには、ユーザーからの不正なプロンプトを排除するフィルタリングやサニタイズ処理を行うことが重要です。不正な文字や特殊文字、実行可能なコードを含む可能性のある入力を拒否するバリデーションを行ったり、悪意のあるコードやスクリプトを無害化するサニタイズ処理が有効です。
・入力内容の制御
ユーザーが入力できるプロンプトをあらかじめ限定し、許可されたプロンプトのみを入力できるように制御することも有効です(ホワイトリスト方式)。ただし、ユーザーからの入力を制限することは、LLMの最大の強みである体験の自由度を制限することになります。プロンプト・インジェクション攻撃への対策は、安全性と自由度のトレードオフと言えるでしょう。
弊社の提供するサービスではユーザーの入力に対してバリデーションを行い、電話番号やメールアドレス等の送信を防止するなどの対策が可能です。また、システムの学習内容をあらかじめ限定することでユーザーに開示する情報を制限できるので、リスクを最小限に抑えることが可能です。 →SELFのチャットボットサービスについて、詳しくはこちらをご覧ください。
◇LLMの創発能力への対応
現状、LLMは進化の途上であり、データ量やパラメータ数を増やすことで創発的に新しいタスクが達成できるようになると研究で報告されています。これはつまり、LLMが開発者ですら期待していなかった能力を自ら学習し、獲得し得るということです。今後、高度なLLMがどのような能力を獲得していくかは予測不可能で、開発者であっても完全にはコントロールできないと言われています。
こうしたLLMの創発能力が常に事業者やユーザーに利するものであればよいのですが、場合によってはこれまで行っていたセキュリティ対策が無効化されたり、不十分なものになる可能性もあります。一度は安全なシステムを構築できたとしても、モデルの性能の進化に伴って、リスクを再評価し、常に対応可能なセキュリティを再構築しなければなりません。
◾︎対策
・システムの監視とインシデント対応
LLMを利用したシステムが想定通りの挙動をしているか、事業者は常にモニタリングしておく必要があります。ログの分析や監視ツールの使用、セキュリティ情報の収集などを行い、異常なパターンや不正なアクセスがないかをチェックします。
また、セキュリティインシデントが発生した場合に備えて、迅速かつ適切に対応するためのプロセスを策定しておくことも重要です。具体的な対応のほか、責任の分担、法的な義務や規制への対応なども必要となります。
◆LLMのビジネス利用には万全のセキュリティ体制を
2023年3月、イタリアではChatGPTがGDPR(欧州一般データ保護規則)に違反するとして、国内におけるデータ処理が一時的に禁止されました。また、中国ではChatGPTの使用が規制されているほか、米国でも非営利団体が商業利用の差止めを要請する動きが出ました。
一方、日本では一部の企業や大学内で規制する動きがあるものの、政府を中心にLLMの利用を推進する意見が目立っています。日本にはLLMの利用を規制する十分な根拠となる法律は現状存在せず、これは今後LLMが原因となって生じるセキュリティリスクに対して明確なガイドラインが存在しないということです。法的な規制が存在しない以上、事業者は自ら最新の情報を収集し、最大限のリスクに対応できる施策を講じなければなりません。
今後のデジタルサービスに不可欠といっても過言ではないジェネレーティブ(生成)AIは、その性能の高さゆえに潜在リスクも大きいと言えます。自社でリスクを最小限に抑えた開発・運用を行う自信がない場合には、専門的な知見と信頼できる実績を持ったパートナーを選ぶことが重要です。
弊社ではAzure OpenAIを利用し、GPTモデルと連携したチャットボットサービス「SELFBOT」を提供しています。無料トライアルも実施中ですので、ぜひお気軽にお問い合わせください。
SELFのライターを中心に構成されているチーム。対話型エンジン「コミュニケーションAI」の導入によるメリットをはじめ、各業界における弊社サービスの活用事例などを紹介している。その他、SELFで一緒に働いてくれる仲間を随時募集中。



