
近年、社内資料などの固有データを利用してLLM(大規模言語モデル)に回答を生成させる「RAGチャットボット」を活用する企業が増えています。RAG(検索拡張生成)はLLMの回答品質を高める上で有効な手法ですが、効果的に運用するためには検索対象となるデータベースの最適化が欠かせません。
この記事では、固有のデータを活用したRAGチャットボットに有用なデータと、データベース構築の注意点について詳しく解説します。
目次
◇RAGチャットボットとは?
RAG(検索拡張生成)チャットボットは、情報検索とテキスト生成を組み合わせた高度なAIチャットボットです。ユーザーの質問(クエリ)に対して、まず関連する情報をデータベースから検索し、その情報を基に回答を生成します。これにより、より正確で詳細な回答を提供することが可能となります。
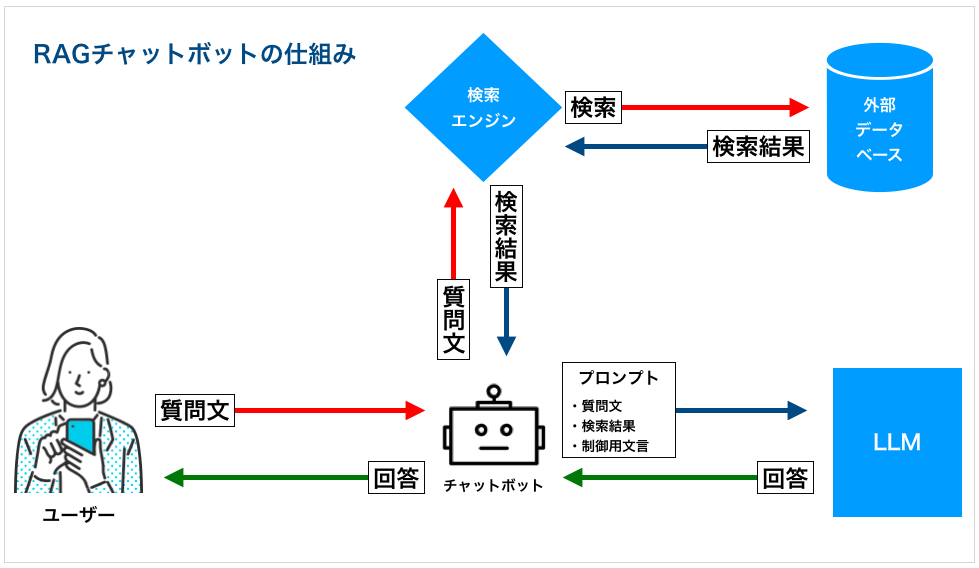
RAGの詳細は、下記の記事をご覧ください。
→RAG:https://self.systems/laboratory-about-rag/
◇どんなデータが有用?
RAGチャットボットはカスタマーサポートや社内業務の効率化など様々な目的で利用されています。検索対象となるデータベースを構築する際は、目的に合わせて必要なデータを選定することが重要です。RAGのパフォーマンスには「検索の精度」が大きな影響を及ぼすため、検索時にノイズとなる余計なデータはできる限り排除すべきです。
ここからは、企業などで利用される一般的なRAGチャットボットで用いられる固有データの例を紹介します。
◆FAQデータ
- 内容:問い合わせフォームなどに寄せられる、よくある質問とその回答のリスト
- ポイント:質問に含まれる類義語、同義語、表記ゆれを想定して作成する
◆製品・サービス情報
- 内容:自社の提供する各製品やサービスの詳細説明、特徴、価格など
- ポイント:正確性の高い最新の情報を記載する
◆サポートドキュメント
- 内容:ユーザーマニュアル、ガイド、トラブルシューティング情報
- ポイント:ユーザーが自分で問題を解決できる情報を含める
◆内部ナレッジベース
- 内容:社内のナレッジベースや専門知識をまとめたドキュメント
- ポイント:特定の社員だけが持つ専門知識をチャットボットに反映する
◆規約・ポリシー等に関する情報
- 内容:プライバシーポリシー、利用規約、返品・交換ポリシー
- ポイント:ユーザーが安心して利用できるよう、法的情報を提供する
◇データベース構築の注意点
上述したようなデータをRAGに用いる場合、注意すべき点があります。
社内に蓄積されたデータの中には、フォーマットやレイアウトに規則性がなく、検索などの機械的な処理に適さないデータ(=非構造化データ)が含まれている可能性があります。RAGでは、検索エンジンが必要な情報を確実に見つけられるよう、データベースの整備(=データの構造化)を行う必要があります。
◆データの前処理
たとえば社内文書の保存によく使われるPDFファイルは、基本的に人間が見る(扱う)ためのデータ形式であり、そのままCSV(カンマ区切り)などの形式に変換しても、必要な情報を適切に取得できない場合があります。要因は様々考えられますが一例として、PDFからテキストを抽出した際に含まれるヘッダー、フッター、ページ番号などの情報がRAGでの検索においてノイズとなる、等の状況が考えられます。
◆人にとってはわかりやすい文書でも…
段組や表など人が読む際には効率的でわかりやすい文書レイアウトも、RAGでの処理には不向きです。たとえば、データを読み取る際に段組みやカラムを無視してしまい、文章の順序がめちゃくちゃになってしまう可能性などが考えられます。そういった場合は、文書レイアウト解析などの処理が必要になります。
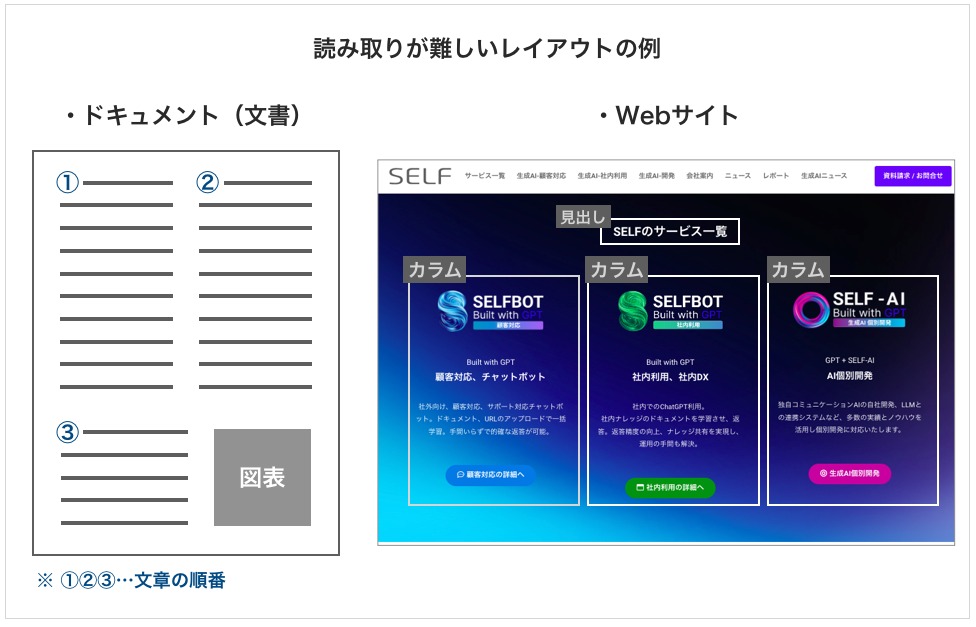
前処理が必要なデータの例
- PDF形式で保存されたデータ
- 段組(カラム)、表など、特殊なレイアウトが用いられている文書
- 図や写真、イラストによる説明が含まれる資料
◆最新モデルなら画像も処理できる?
画像データをRAGで処理する際には、画像の内容を説明したテキストデータを用意するなどの工夫が必要です。最近はGPT-4oなど画像の処理も可能なマルチモーダルの言語モデルが登場していますが、RAGは言語モデルだけでなく検索モデルや埋め込み(ベクトル化)モデルなどの複数のモデルを組み合わせたアーキテクチャです。つまり言語モデルが画像データを処理できるからといって、RAGで画像データを利用できるわけではないのです。
また、画像内に含まれるテキストをデータとして利用したい場合は、OCR(光学的文字認識)による処理でテキストを抽出する必要があります。
◆定期的な見直しも重要
必要なデータをコンピュータの読み取りに適した形で準備してデータベースを構築したとしても、実際に運用した際に思い通りの挙動になるとは限りません。最終的には、ユーザーからの質問に対してボットがどのような回答を出力しているかを人の目で検証し、データの内容を調整していく必要があります。
また、データベースに含まれる情報の更新も怠ってはいけません。ボットが最新の情報に基づいて回答を出力するために、定期的にデータを更新する必要があります。更新の際は新しい情報を追加するだけでなく、追加した情報と矛盾し得る古い情報を排除することも大切です。
◇データベース整備のコストを抑えるには
RAGは、LLMを特定の目的に特化させる上でファインチューニングよりもはるかに手軽な手法として注目されています。しかし、RAGを用いたチャットボットで思い通りの効果を実現するためには、データベースの整備が欠かせません。データベースの整備作業は、RAGに利用する資料(データ)が多くなるほど、コストとして重くのしかかってくるでしょう。
◆データ構造化のコストが大きい
たとえばPDFファイルをRAGに向けて構造化する場合、そのファイルがテキストデータをPDF化したものなのか、文書をスキャンした画像データなのかによって、必要な処理が変わります。また、その文書に含まれるひとつひとつの要素(段組み、表、画像、階層構造など)によっても処理が異なります。それらを把握し、ひとつひとつ対応していくのは決して楽な作業ではないでしょう。
◆RAGチャットボットサービスの利用
RAGチャットボットはAPIを利用すれば誰でも構築することができます。
しかし上述の通り、RAGチャットボットにはデータベース構築、運用に関する専門知識と作業が欠かせません。「RAGチャットボットを使ってみたいけど自社でデータベース整備をするのは大変」と言う場合は、外部サービスを利用するのが効率的です。

◆生成AIチャットボット「SELFBOT」
弊社(SELF株式会社)の提供するSELBOTはChatGPTと連携したRAGチャットボットサービスです。専用の管理コンソールからPDFを含む各種ドキュメント(Word、Excel、パワーポイント資料など)やWebサイトのURLをアップロードするだけで、自動的に下記のような処理を行いデータを最適化。あっという間にデータベース構築が完了します。
- ドキュメントのレイアウトを解析
- 文書の階層構造(表題、見出し、本文の関係など)を把握
- 画像、表に含まれるテキストを抽出
・豊富な実績を基にデータベース最適化をサポート
SELFBOTを導入いただいた企業様には、専門知識を持つスタッフがデータベース構築から効果的な運用に至るまでを手厚くサポートさせていただきます。
また、無料の体験セミナーやトライアルプランもご用意しておりますので、RAGチャットボットの導入、運用に関して気になる点がございましたら、ぜひお気軽にお問い合わせください。
SELFのライターを中心に構成されているチーム。対話型エンジン「コミュニケーションAI」の導入によるメリットをはじめ、各業界における弊社サービスの活用事例などを紹介している。その他、SELFで一緒に働いてくれる仲間を随時募集中。



