
近年、大きな話題となっているChatGPTをはじめとする対話型AI。
その革新性をビジネスシーンに活用すべく、生成AIと連携した様々なツール、サービスが急速に普及し始めています。中でも生成AIと連携したチャットボットは、LLM(大規模言語モデル)の機能性を手軽にカスタマーサポートや業務効率化に活かすことができるため、大きな注目を集めています。しかし、生成AIチャットボットを適切に事業活用するためには、解決しなければならない課題も存在します。
この記事では、生成AIチャットボットの回答品質を向上させるRAG(検索拡張生成)について解説します。
目次
◇生成AIチャットボットの課題
現在、ビジネス分野で急速に広がっている生成AI利用。
生成AIと連携したチャットボットなどのツールを活用すれば、下記のような課題に対して効果的な施策が可能です。
- カスタマーサポートの自動化
- 社内ヘルプデスク業務の自動化
- 社内ナレッジ共有の効率化
- 営業・マーケティング支援
LLMの自然言語処理を利用しているため、ユーザーからの幅広い質問に自然な文章で回答することができ、従来のチャットボットのようなシナリオ構築の手間もありません。
しかし、LLMの特長である創造的なテキスト生成が、ビジネス活用においては深刻な問題を引き起こしてしまうこともあるのです。

◆LLMが学習済みの情報は「広く浅い」
LLMとは、事前に大規模なデータセットを用いてトレーニングされた言語モデルのことです。
Web上のテキストなどの幅広い知識を有し、様々な質問に自然な言い回しで回答を提供します。しかし、当然のことながら世の中のあらゆる情報がインプットされているわけではなく、トレーニングデータに含まれていない情報は正しく答えられません。公開されているChatGPTなどの対話AIサービスも、一般的な知識から一歩踏み込んだ専門的な情報については、正確な情報を持っていません。
Web検索機能を備えた生成AIサービスであれば、ネットに公開されている情報を検索して回答を生成することは可能ですが、当然ながら一般に公開されていない社内情報まで把握することはできません。つまり、企業がLLMをカスタマーサポートや社内ナレッジ共有に利用するには、LLMに何らかの方法で追加の情報を与える必要があります。
◆ハルシネーションへの懸念
LLMをビジネスに活用する上で、最大の懸念とも言われるのが「ハルシネーション(人工知能の幻覚)」の問題です。これはLLMが「事実と異なる情報をあたかも事実かのように回答してしまう」現象です。顧客や取引先が利用する可能性のあるチャットボットでこの現象が起こってしまうと、信用の低下につながり、重大な損失を生みかねません。
しかも残念なことに、現時点(2024年3月)でハルシネーションを完全に防止できる確実な方法は見つかっていません。現状はハルシネーションが起こる可能性を念頭に置き、なるべくハルシネーションを抑制するしかありません。
LLMを利用したチャットボットを導入する際には、どのようなハルシネーション対策が施されているか、という点を確認することが必須といえるでしょう。
ハルシネーションについては、こちらの記事も併せてご覧ください。

◇RAGで生成AIチャットボットの精度向上
上述したLLMの持つ課題への対処法として注目されているのがRAG(検索拡張生成)です。
◆RAG(検索拡張生成)とは
RAG(Retrieval Augmented Generation)はその名の通り「検索」と「生成」を組み合わせることで、生成AIチャットボットの精度を大幅に向上させる技術です。
RAGでは、LLMが事前に学習済みのデータセットとは別の「データベース」を用意します。ボットがユーザーから質問を受けた際に、その質問に関連する情報をデータベース内から検索し、その検索結果をLLMの生成に利用することで回答の精度を高めるのです。
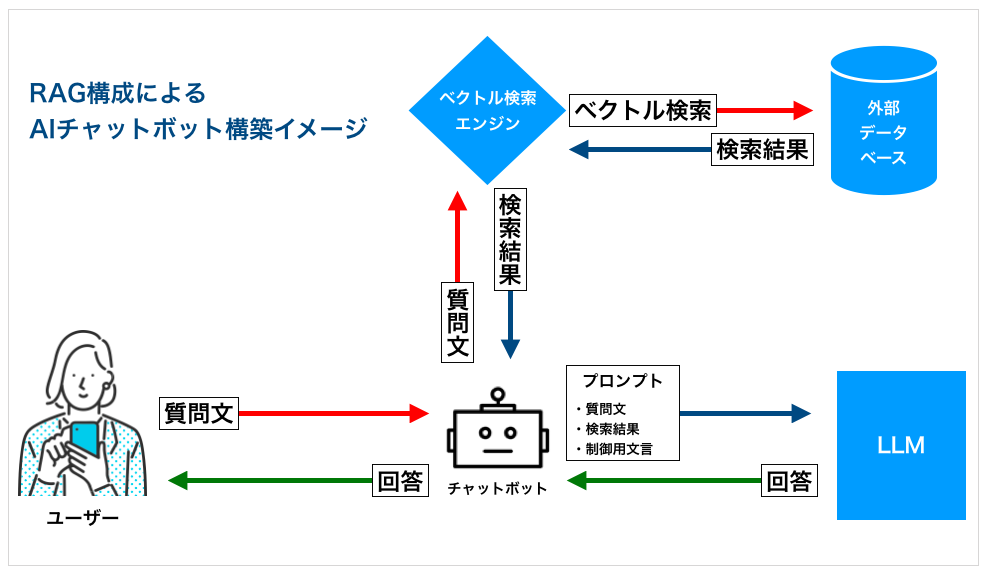
RAGの仕組みは、よく「クローズブックテスト」と「オープンブックテスト」にたとえられます。つまり、「教科書持ち込み不可の試験で、記憶だけを頼りに問題を解く」か「教科書持ち込み可の試験で、教科書を参照しながら問題を解くか」の違いです。どちらが正答率が高くなるかは想像に難くありません。
◆ファインチューニングとの比較
生成AIの回答精度を高める手段は、RAGだけではありません。よく知られているのが、訓練済みのモデルに追加データを与えモデルの持つ知識を拡張する「ファインチューニング」です。しかし、ファインチューニングを行うには以下のような課題があります。
- 大量のトレーニングデータが必要
- 正しい回答を得るにはデータセットの調整を繰り返すなど、試行錯誤が必要
- 高度な計算能力、ストレージ、メモリを有するマシンが必要
上記の課題から、ファインチューニングは機械学習において専門的な技術と十分な環境が整っていなければ難しい手法です。一方RAGは、ファインチューニングに比べて少ないデータで精度を向上させることができ、データを検索する仕組みさえあれば手軽に固有の知識を持つ生成AIチャットボットを構築することが可能です。
◆エンベディングによる検索精度の向上
RAGにおける検索の精度を向上させる技術が「エンベディング(Embbeding)」です。エンベディングとは、単語や文章をベクトルに変換する技術です。ベクトルに変換することで、単なるキーワード検索ではなく「意味による検索(セマンティックサーチ)」が可能となります。これにより、質問文の意味を汲み取った効率的なデータ検索が可能となり、そのデータを参照して回答生成を行うことで、回答品質の向上が実現できるのです。
◆RAGの課題
このように、RAGは生成AIチャットボットの精度を大幅に向上させることができる技術ですが、以下のような課題もあります。
・データベースの品質管理
まず、回答生成の根拠となるデータの品質管理が重要です。検索したデータに誤った情報や古い情報が含まれていた場合、当然ながら生成された回答にもその内容が含まれることになります。そのため、データベース内の情報は常に正確に、最新の状態を保つ必要があります。
・適切なドキュメント分割
RAGを効果的に行うためには、学習データとなるドキュメントを適切な大きさに分割してエンベディングする必要があります。このデータの大きさの単位をチャンクといい、生成された回答の品質向上には適切なチャンクサイズを設定することが重要です。チャンクの大きさによっては、必要な情報が途切れてしまったり抜け落ちてしまう可能性があり、ボットの回答精度に影響を及ぼす要因となります。
・画像や表などのデータへの対応が難しい
一般的なRAGはドキュメントデータをベクトル化しセマンティック検索を行う手法です。そのため、画像や表データ(テーブルデータ)に対応するためには、まずそれらのデータをベクトル検索可能なデータに変換(構造化)する必要があります。これにはRAGとは異なるデータ構造化の技術が必要となります。また、画像内に含まれている文字情報を抽出したい場合にはOCR(光学的文字認識)などの処理が必要となります。
RAGは生成AIチャットボットの精度向上に効果的な手法ではあるものの、現状では上記のような課題があることも認識しておかなければなりません。
◇高精度のチャットボットを手軽に導入
RAGはLLMの機能をチャットボットに活かすための一般的な手法として、多くの製品やサービスに取り入れられています。しかし、上述した通り、RAGを効果的に行うためにはチャンクサイズの設定やデータの品質管理、構造化などのノウハウが必要です。それらの手法は一通りではないため、導入を検討する際にはどのような手法でRAGを行なっているのか、確認しておくことが重要といえるでしょう。
◆RAGを備えた生成AIチャットボット
SELF株式会社の提供する「SELFBOT」はRAGを備えた生成AIチャットボットです。
ドキュメントファイルやWebページのURLを登録するだけでデータ連携が完了し、ハルシネーションを抑えた高精度のチャットボットを構築できます。
- エンベディング+RAG(検索拡張生成)により精度の高い回答出力
- 自動データ学習機能で手軽な導入・運用が可能
- Azure OpenAI Service利用によりセキュリティも万全
- 多機能かつ直感的に操作可能な管理画面を提供
- 多数の導入実績に基づく、手厚い運用サポート
◆無料トライアル実施中
SELFBOTは無料トライアルを実施中です。
SELFBOTの全機能を、実際のサービス環境下にてご利用頂けます。WEBサイト上でのカスタマーサポート、社内ナレッジ検索などの用途でお試し頂くことが可能です。詳細は下記のお問い合わせページよりお気軽にお問い合わせください。
統合AIサービス「SELFBOT」を提供するSELF株式会社のマーケティングチーム。同社の専門分野であるRAGの技術や最新の市場状況を解説する記事をはじめ、AIエージェント、AIアバターなど同社サービスと関連の深い記事を発信しています。



