
近年、大きな話題になっている生成AI。中でも、ChatGPTをはじめとするLLM(大規模言語モデル)を使ったサービスやAIツールが急速に普及し始めています。
しかし、生成AIの利用にはいくつかの懸念もあり、その中でも頻繁に取り沙汰される問題に「ハルシネーション (人工知能の幻覚)」があります。
この記事では、ハルシネーションとはどういった現象なのかを解説し、ハルシネーションを抑える方法を紹介します。
目次
◇ハルシネーションとは?
「ハルシネーション」とは、人工知能(AI)が事実と異なる情報を生成してしまう現象のことです。人工知能がまるで幻覚を見ているように事実でないことを事実のように語る様子から、「Hallucination=幻覚」と名付けられました。2022年、対話型AIのChatGPTが公開されると、その革新性に注目が集まるとともにAIが誤った情報をさも事実であるかのように出力する現象が続々と確認されました。専門家らはAIの出力した誤情報をユーザーが信じ込んでしまうことの危険性や権利侵害につながる恐れに警鐘を鳴らし、結果として「ハルシネーション」という言葉は一般にも認知されるようになりました。
◆ハルシネーションはなぜ起こるのか
ハルシネーションが起こる原因は複数あると考えられています。
LLM(大規模言語モデル)は事前に学習した膨大なデータから様々な情報(テキスト)を生成しますが、そもそも情報の正誤を判定することはできません。たとえばWeb上のデータなどをトレーニングに使った場合、そこに含まれている誤情報や創作、古い情報もそのまま学習してしまいます。そうして学習した事実と異なる情報をもとにテキストを生成することがハルシネーションを引き起こす一因であるとされています。
また、LLMは文章や単語の意味を理解してテキストを生成するわけではありません。学習した膨大なデータを基に統計的に正しそうな単語の連なりを抽出し、自然な文章に整形して出力しているにすぎません。つまりハルシネーションとは、言葉の意味を理解していないAIが人間と同等の自然な言葉選びだけを習得した結果、事実に基づかない情報をいかにも事実らしく話してしまう現象といえます。
◆ハルシネーションの分類
ハルシネーションには大別して以下の2つのパターンがあると言われています。
①学習データに基づいてはいるものの、事実とは異なる情報を生成してしまう
②学習データに存在しない情報をAIが生成してしまう
①は学習データ自体に誤りや偏り(バイアス)が含まれている場合、②はAIのアーキテクチャや学習プロセスに問題がある場合と言えます。ただ、ChatGPTやGoogle BardなどのAIチャットではAIがどんな情報を参照して回答を生成したのか、ユーザーにはわかりません。そのためハルシネーションと思われる現象が発生しても、①と②のどちらにあたる事象なのか判断するのは困難でしょう。
◆ハルシネーションが原因で起こったトラブル
ハルシネーションはAIへの信頼性を損なう現象であるため、その現象が発生しうるという事実そのものがAI技術の普及を妨げる重大な問題であるといえます。
また、AIが生成した誤情報をユーザーが信じ込む、あるいは誤情報と分かった上で故意に拡散することで名誉毀損や差別などの人権侵害につながったり、人々の意思決定の誤りを招く恐れもあります。
・ハルシネーションによる名誉毀損訴訟
実際にChatGPTのハルシネーションがきっかけとなって名誉毀損(きそん)の訴訟も起こっています。
米ジョージア州のラジオ番組の司会者を務めるマーク・ウォルターズ氏は、ChatGPTによって名誉を毀損されたとして開発元のOpenAIを提訴しました。
訴状によると、ChatGPTはある訴訟について質問したユーザーに対して、ウォルターズ氏が詐欺や横領を働いて告訴されたとする誤った回答を生成したとされています。その訴訟は実際はまったく別の人物に対して起こされたもので、ウォルターズ氏は一切関わっていませんでした。
ウォルターズ氏は、虚偽の内容によって名誉を毀損されたとしてOpenAIを訴えました。OpenAIがハルシネーションに絡む名誉毀損で訴えられた初めての事例となりました。
・弁護士が裁判で「存在しない判例」を引用
米ニューヨーク州では、現役の弁護士が裁判で用いた書類にChatGPTが生成した誤情報が多数含まれていたとして騒動になりました。弁護士のスティーブン・シュワルツ氏は、法廷に提出する文書の作成にChatGPTを使用。その際にハルシネーションと思われる事象が発生し、実際には存在しない訴訟の判例が多数記載される事態となりました。その生成結果を自ら調べることなく法廷に提出してしまったことで、シュワルツ弁護士は判事から2時間近い尋問を受けました。
この件では文書に含まれる誤情報が早々に判明したため、司法判断に影響を与えるような事態にはなりませんでした。しかし、実際に弁護士が法廷で提出した文書にAIの生成した誤情報が含まれていたと言う事実は、ハルシネーションがいかに社会にとって重大な問題を孕んでいるかを示唆しています。
◇AIチャットボットのハルシネーション対策
ここまでに述べたように、ハルシネーションはすでに現実社会の中で様々な問題を引き起こしています。しかしその対策については未だ研究が進められている段階であり、ハルシネーションを防止する確実な方法は現時点(2024年1月)では見つかっていません。
では私たちは、ハルシネーションという解決手段のない問題を孕んだまま急速に普及していくLLMというテクノロジーと、どう向き合っていけば良いのでしょうか。
まず前提として、ユーザーひとりひとりが「AIの生成した結果を鵜呑みにしない」という意識を持つこと、組織や社会全体でAI利用のルールやガイドラインを作成し、リテラシーを高めることが重要です。
また、ハルシネーションを完全に防止する方法はないものの、最小限に抑制する技術的な手法は存在します。ビジネスなど大きな責任が発生し得る場面でLLMを利用する場合には、ハルシネーションを抑えるためにでき得る限りの対策をとることが重要です。ここからは、LLMを用いたAIチャットボット構築におけるハルシネーションの抑制方法を紹介します。
◆ファインチューニングで対策できる?
事前学習済みのAIモデルを別のデータセットで再トレーニングし、特定のタスクにおけるパフォーマンスを高める手法を「ファインチューニング(追加学習)」といいます。
たとえばChatGPTなどの事前学習済みのモデルに独自のデータを追加で学習させ、特定のタスクに対応できるようにする、といった調整がファインチューニングにあたります。モデルに新たな知識を与えることで特定分野の知識に対する解像度が上がり、回答の精度を高めることが可能となります。ただし、LLMが回答を生成する際に、追加学習させた情報が必ずしも生成結果の根拠となるわけではありません。LLMは事前学習データと追加学習データを併せ、最頻値的な回答を生成するため、なおも生成結果に誤った情報が含まれてしまう可能性は残ります。
ファインチューニングによるハルシネーションの抑制は、LLM活用の可能性を拡張するための重要なテーマとして様々な研究が行われていますが、現時点では効果的にハルシネーションを抑えた運用が可能となる段階には至っていないといえます。
◆プロンプトエンジニアリングによる対策
LLMに与えるプロンプト(自然言語による質問文や命令、指示)によって、回答の精度を高めることが可能です。Google DeepMindの研究によると、「深呼吸をして、この問題に一歩ずつ取り組もう」という一文をプロンプトに加えたところ、LLMの数学的問題における正答率が34%→80%に向上したそうです。このように、LLMのパフォーマンスを向上させるためのプロンプト構築をプロンプトエンジニアリングと呼び、これによってハルシネーションをある程度抑えることができます。
たとえば、LLMと連携したAIチャットボットが特定の分野について頻繁に誤った情報を生成してしまう場合、「〇〇についての情報は提示しないでください」とプロンプトに加えることで情報の正誤にかかわらず、その分野に関する情報提供を制限することが可能です。
ただし、プロンプトでハルシネーションを防ぐためには、モデルの回答を制限するプロンプトを毎回与える必要があります。また、同時に複数の指示を与えたり、プロンプトが長文になることでモデルがプロンプトの内容を理解しきれず、一部の指示を無視したような挙動をすることもあります。ハルシネーション対策としては一定の効果があるものの、確実に抑制できる手法とはいえません。
◆LLMのグラウンディング
ハルシネーションを抑制する方法として、現時点でもっとも有効とされている方法がLLMのグラウンディングです。そもそもAIには、言葉(記号)と実世界の事柄を関連づけて理解することができない「シンボル・グラウンディング問題」と呼ばれる問題が存在します。このシンボル・グラウンディング問題を解消、緩和する手法がグラウンディング(接地)です。
LLMの分野において「グラウンディング」は、特定のデータベースに含まれる情報のみに基づいてLLMに回答を生成させる手法を指します。つまり、LLMを活用する側が「どの情報源を基に回答を生成するか」を指定することで、生成結果の正確性を高めるのです。これは、追加のデータセットによってモデル自体を調整するファインチューニングとは異なる手法です。
・RAG構成で回答精度の向上を図る
具体的にグラウンディングを行う手段として、テキストデータベースをエンべディング(ベクトル化)する技術とベクトル検索を組み合わせたRAG(Retrieval Augmented Generation)構成が注目されています。RAGは米Meta社(旧Facebook)が2020年に論文の中で発表した手法で、日本語では「検索拡張生成」と呼ばれます。つまり、LLMの自然言語処理技術(NLP)に外部データベースのベクトル検索を組み合わせることで、LLMが生成する回答の精度、正確性を向上させようというAIフレームワークです。
またベクトル検索はセマンティック検索(意味による検索)とも呼ばれ、単なるキーワード検索よりも質問者の意図に沿った検索結果を得られる手法です。この手法を取り入れることで、LLMが把握することの難しい質問文の意味に適合する情報源を見つけ出し、回答生成の根拠とすることができるのです。
たとえば、LLMと連携したチャットボットにRAG構成を実装すると、主に2つのメリットがあります。
・AIが最新の信頼できる事実を基に回答を生成できる ・回答の根拠となったデータを特定できる
チャットボットをLLMと連携させただけでは、そのボットはLLMが生成したテキストをそのまま出力するだけとなり、ハルシネーションは抑制されません。一方RAG構成を実装したボットの場合、LLMが事前に学習したデータとは別のデータベースから情報を検索し、その検索結果に基づいた回答を生成することができます。たとえるなら、試験の際に記憶だけを頼りに問題を解くのではなく、教科書を見ながら解答するようなものです。
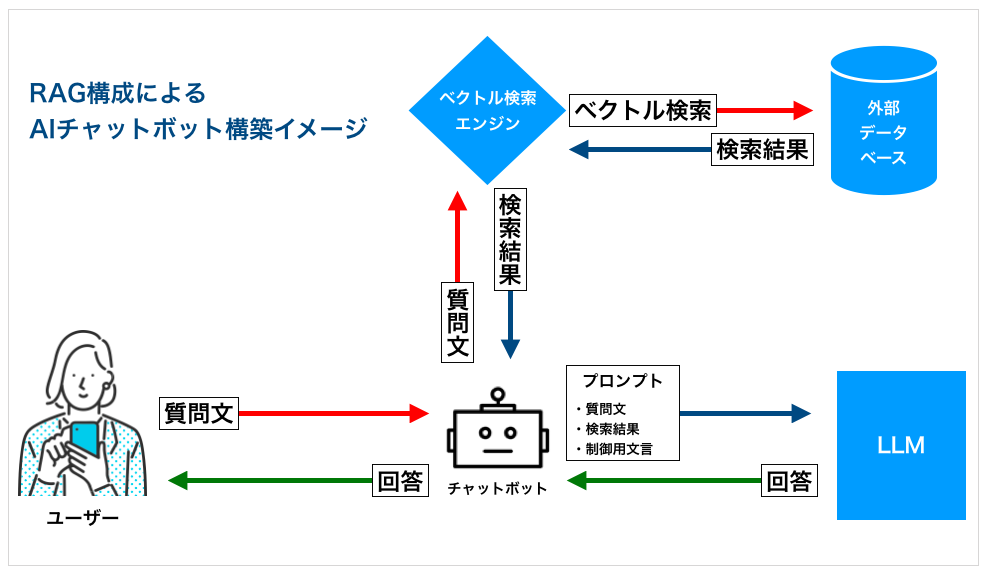
・回答の根拠となった情報を特定可能
RAG構成を導入することで、ボットがデータベース中のどのデータを用いて回答したかを特定することができるため、その内容を確認して情報の正確性を判断したり、正確性に欠けるデータを修正するなどの改善が容易になります。そうして検索対象となるデータベース自体の正確性を高めていくことで、ハルシネーションが起こりにくいAIチャットボットを構築することが可能となるのです。
これが現時点で最も有効とされるハルシネーション対策、RAG構成によるLLMのグラウンディングです。
・100%の正確性は実現困難
とはいえ、RAGを行ってもLLMの回答生成に100%の正確性を求めることはできません。当然ながら、外部データベースに含まれない情報をユーザーが得ようとした場合、LLMは従来通り、モデルが事前に学習済みの情報から回答を生成します。その場合、やはりハルシネーションが発生する可能性はあるのです。
また、大規模なデータセットを検索する場合、その検索結果を適切な大きさに分割(インデックス化)してLLMに参照させる必要があります。その際に必要な情報が抜け落ちてしまったり、本来は連続する文章が途切れてしまったりすることで、AIが情報の意味を十分に理解できず、ハルシネーションが起こることもあります。
このようにRAGによるグラウンディングを行ったとしても、ハルシネーションが起こる可能性を完全には排除できない、ということを理解しておく必要があります。
◇信頼できるAIサービスを選ぶ
ここまでに述べたように、現状ハルシネーションを防止する完全な方法はありません。しかし、LLMのグラウンディングやプロンプトエンジニアリングによって、AIチャットボットがユーザーに提供する情報の精度を高めることは可能です。
◆ハルシネーション対策が可能なAIチャットボット
「SELFBOT」は、SELF株式会社が開発したChatGPT連携チャットボットです。
社内情報など独自のデータセットを用いたRAG構成のAIチャットボットを手軽に構築可能です。ユーザーの入力文と学習データをベクトル化し、セマンティック検索(意味による検索)を行うことによって精度の高い回答の出力を実現。さらに、回答の根拠となったリソースを提示する機能によって、ユーザーが情報の正確性を確認することも容易です。
・会話ログ画面に「類似性スコア」を表示
専用の管理画面にはボットとユーザーの会話ログを閲覧できる機能があり、項目の一つとして回答精度の指標となる「類似性スコア」が表示されます。これはユーザーからの入力と学習データをベクトル化した上で双方の類似性を数値化したものであり、このスコアが高いほどAIがユーザーの質問内容に対して適切なデータを参照して回答していることになります。つまり、「類似性スコア」を見ることで回答精度を高めるためにどのデータを改善すべきか容易に判断できるのです。
・多数の導入実績に基づく運用サポート
SELFBOTは、様々な分野の企業様に導入いただいています。クライアント様によって様々に異なる課題に対応する中で、弊社ではデータセットの構築やプロンプトエンジニアリングに関する多くの知見を蓄積してきました。ハルシネーション対策をはじめ、AIチャットボット運用におけるあらゆる課題解消のために、充実したサポートを提供することが可能です。
SELFBOTの導入事例については下記のページをご覧ください。
→導入事例紹介ページ
・無料トライアル実施中
SELFBOTは無料トライアルを実施中です。
SELFBOTによる会話体験を、実際のサービス環境下にてご利用頂けます。WEBサイト上でのカスタマーサポート、社内ナレッジ検索などの用途でお試し頂くことが可能です。詳細は下記のお問い合わせページよりお気軽にお問い合わせください。
SELFのライターを中心に構成されているチーム。対話型エンジン「コミュニケーションAI」の導入によるメリットをはじめ、各業界における弊社サービスの活用事例などを紹介している。その他、SELFで一緒に働いてくれる仲間を随時募集中。



